AWK 工作流程
对于会的人来说,AWK 极其简单,对于不会的人来说,AWK 简直难如登天。
那是什么原因导致了两种极端?
想想,我们为什么如此的胆小,如此的担心受怕?
面对未知的事物,我们从来不敢越雷池一步,但对于会的已知的,我们却易如反掌。
是什么原因导致了两者的不同?
这个问题困惑我好久,直到有一天,我发现,对于会的已知的,我基本都知道它们是怎么工作的!
那么,对于 AWK,如果我们要熟练掌握,就必须知道它是怎么工作的,也就是它的工作流程。
AWK 工作流程
如果你想成为一个 AWK 专家,你必须知道 AWK 的内部是如何工作的。
AWK 的工作流程,说起来真的很简单:
开始 -> 读取 -> 执行 -> 读取 -> 执行 -> .... -> 读取 -> 执行 -> 结束
如果用一张图画出来,大概就是下面这个样子
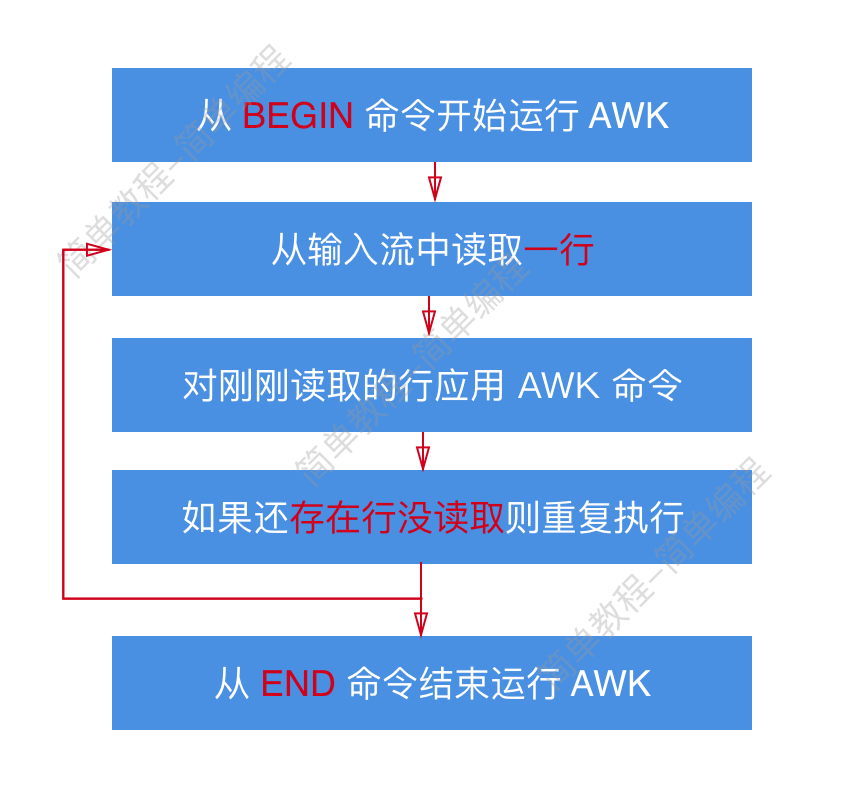
读取
AWK 从输入流中读取 一行,然后保存在内存中
这个输入流可以是 标准输入流,可以是一个 文件,还可以是一个管道
执行
执行就是把 BEGIN 和 END 之间代码按照顺序应用到刚刚读取的 一行 上。
默认情况下,针对输入流中的每一行,AWK 命令都会执行一次,当然了,我们可以使用一些 代码 来改变这种默认行为
重复
如果输入流中还存在未读取的行,那么会重复 读取 -> 执行,直到输入流中不存在行为止,也就是遇到 文件结束符 为止。
程序结构
对照上面这张图,我们来理一理 AWK 的程序结构
BEGIN 块
BEGIN 关键字表示 AWK 程序的开始,它的使用语法如下
BEGIN {awk-commands}
BEGIN 语句只会执行一次。
我们可以把一些要做的初始化工作放到 BEGIN 语句中,比如变量的初始化。
BEGIN 是 AWK 的一个关键字,而且必须 大写。
需要注意的是: BEGIN 是可选的,如非必要,可以直接省略。
AWK 主体代码
AWK 主体代码是 AWK 程序最重要的部分,AWK 会把从输入流中读取的每一行都应用到 AWK 主体代码
也就是说,对于输入流中的每一行,都会执行一次 AWK 主体代码
AWK 主体代码有着如下的语法
/pattern/ {awk-commands}
AWK 主体代码可以有一个模式 /pattern/ 开头,这个模式可以对将要执行的输入行进行一些限制和过滤。
对于 AWK 主体代码,有三点需要注意:
- 模式是夹在两个正斜杠 (
/) 之间的 - AWK 主体代码没有任何关键字标识
- AWK 主体代码也是可选的,可以忽略
END 块
END 关键字用于标识 AWK 程序的结束,通常用于处理一些结尾工作
它的语法结构如下
END {awk-commands}
END 和 BEGIN 一样都是 AWK 的关键字,而且都必须是大写的。
同样的 END 块和 BEGIN 块一样,都是可选的。
范例
讲了那么多,我们用一段 AWK 代码来演示下刚刚我们学习的 AWK 工作流程和 AWK 程序结构
我们首先创建一个文件 employee.txt,它包含了我们公司雇员的一些信息
这个 employee.txt 文件有着以下结构:
1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23
对照着上面的程序结构,我们来讲讲可以被 AWK 处理的程序的一般结构:
- 每个雇员独占一行
- 每个雇员都包括以下字段:序号,名字,部门,年龄
- 每一行的多个字段之间使用空白作为分隔符,空白分隔符一般是空格 (
) 或者制表符\t
然后,我们想要获得以下输入结果
序号 姓名 部门 年龄 ------------------- 1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23 -------------------
分析
从上面的结果中可以看出,整个输出结果分为三大部分
-
表头
序号 姓名 部门 年龄 -------------------
-
数据
每个雇员一样,且有着以下的结构
1. 张三 技术部 23
-
表尾
-------------------
根据我们刚刚学到的知识,AWK 程序结构分为三大部分,BEGIN 和 END 只会执行一次,看起来刚好可以用来输出表头
而 AWK 主体代码,是针对每一行执行的,因此,刚好可以用来输出数据。
表头
为了输入表头,我们可以使用下面的 Shell 语句
[www.twle.cn]$ awk 'BEGIN{printf "序号\t名字\t部门\t年龄\n----------------------------\n"}'
因为表头部分不需要处理输入文件,也不需要处理输入文件中的每一行,所以 AWK 主体代码都是可以忽略的,甚至包括输入文件都是可以忽略的
运行上面的代码,输入结果如下
序号 名字 部门 年龄 ---------------------------
数据
对比想要的结果和输入的文件,可以看出输出结果并并没有对每一行做特殊处理,直接显示就好
因此,只需要在 BEGIN 块后面直接添加 {print} ,添加完代码如下
[www.twle.cn]$ awk 'BEGIN{printf "序号\t名字\t部门\t年龄\n----------------------------\n"}{print}'
当然了,如果直接这样运行,会发现程序被卡住了
为什么呢?
因为它卡在了读取一行数据这里,它在等待我们输入数据
为了提供输入数据,我们可以在整个 shell 命令后直接追加文件路径和文件名 employee.txt
添加完之后的 shell 代码如下
[www.twle.cn]$ awk 'BEGIN{printf "序号\t名字\t部门\t年龄\n----------------------------\n"}{print}' employee.txt
运行上面的命令,输入结果如下
序号 名字 部门 年龄 ---------------------------- 1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23
表尾
最后,从想要的结果中可以看出,整个结果最后还有一行虚线,这个,我们可以通过 END 语句来实现
因为 END 语句和 BEGIN 语句类似,我们就直接给结果了
[www.twle.cn]$ awk 'BEGIN{printf "序号\t名字\t部门\t年龄\n----------------------------\n"}{print}END{printf "----------------------------\n"}' employee.txt
运行上面的命令,输出结果如下
序号 名字 部门 年龄 ---------------------------- 1) 张三 技术部 23 2) 李四 人力部 22 3) 王五 行政部 23 4) 赵六 技术部 24 5) 朱七 客服部 23 ----------------------------